메트릭
최종 수정: 2026. 1. 16.
메트릭
메트릭 탐색기를 사용하여 시스템 및 애플리케이션 메트릭을 시각화하고 분석하는 방법을 안내합니다.
개요
메트릭 탐색기는 모든 Agent Cluster에서 수집된 메트릭을 쿼리하고 시각화하는 도구입니다.
주요 기능
| 기능 | 설명 |
|---|---|
| PromQL 지원 | Prometheus 호환 쿼리 언어 |
| 다양한 시각화 | 라인 차트, 막대 그래프, 히트맵 등 |
| 멀티클러스터 | 모든 클러스터 메트릭 통합 조회 |
| 집계 함수 | sum, avg, max, min, rate 등 |
| 레이블 필터 | 클러스터, 네임스페이스, 파드별 필터 |
메트릭 탐색기 접근
- 좌측 메뉴에서 Metrics 클릭
- 메트릭 탐색기 화면이 표시됩니다
화면 구성
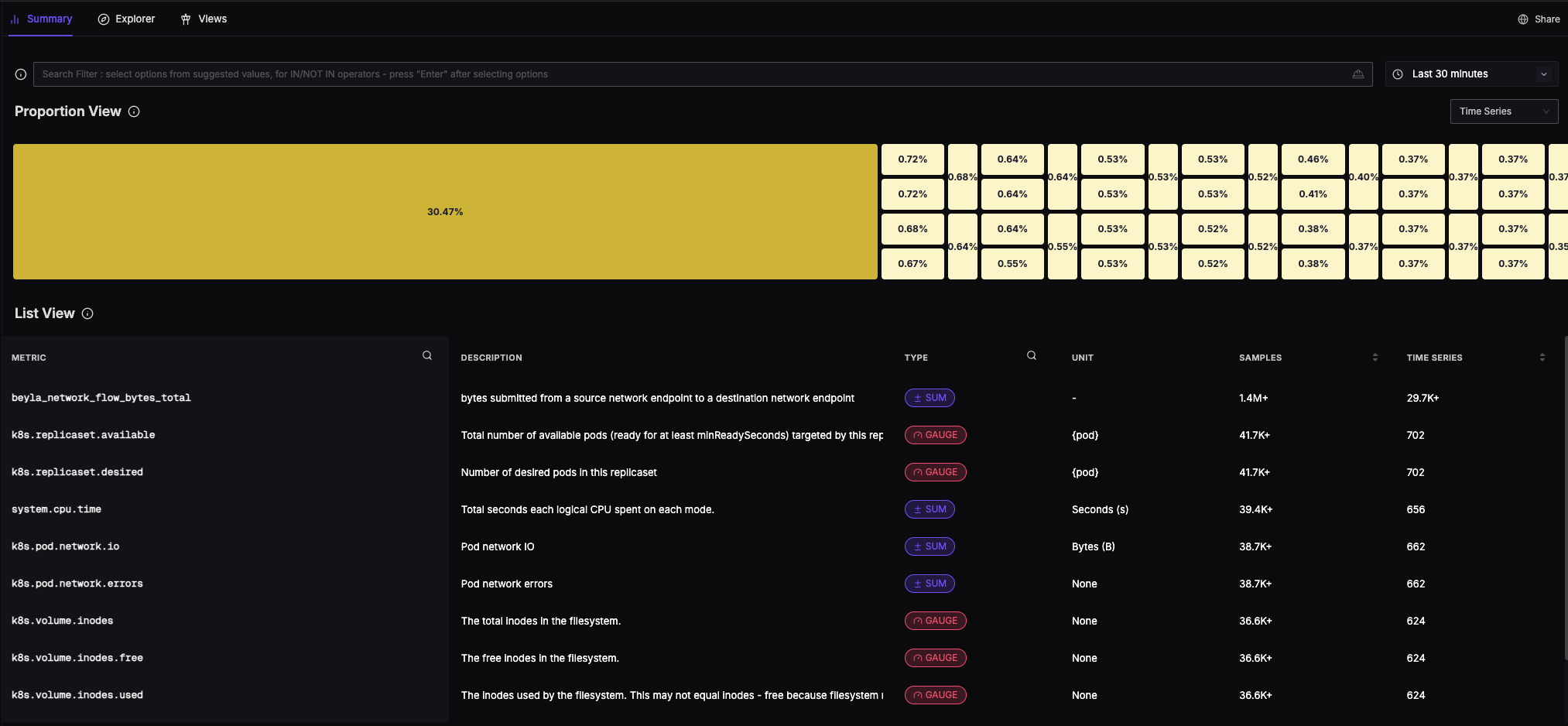
쿼리 빌더
코드 없이 메트릭을 쿼리할 수 있는 시각적 도구입니다.
기본 사용법
- Metric 드롭다운에서 메트릭 선택
- Filters 섹션에서 레이블 필터 추가
- Aggregation 선택 (sum, avg, max 등)
- Group By 로 그룹핑 기준 선택
- Run Query 클릭
예시: CPU 사용량 조회
- Metric:
system_cpu_utilization - Filters:
k8s_cluster_name = production-cluster - Aggregation:
Average - Group By:
k8s_node_name
PromQL 쿼리
고급 사용자를 위한 PromQL 직접 입력 기능입니다.
기본 쿼리
# 메트릭 조회
system_cpu_utilization
# 레이블 필터
system_cpu_utilization{k8s_cluster_name="production"}
# 여러 조건
system_cpu_utilization{k8s_cluster_name="production", k8s_node_name=~"node-.*"}집계 함수
| 함수 | 설명 | 예시 |
|---|---|---|
sum |
합계 | sum(container_memory_usage) |
avg |
평균 | avg(node_cpu_utilization) |
max |
최대값 | max(container_cpu_usage) |
min |
최소값 | min(response_time_seconds) |
count |
개수 | count(up) |
그룹핑
# 네임스페이스별 메모리 사용량 합계
sum by (k8s_namespace_name) (container_memory_usage_bytes)
# 클러스터별 CPU 사용량 평균
avg by (k8s_cluster_name) (system_cpu_utilization)Rate 함수
카운터 메트릭의 증가율 계산:
# 5분 동안의 요청 rate
rate(http_server_request_total[5m])
# 1분 동안의 에러 rate
rate(http_server_errors_total[1m])연산
# 에러율 계산
sum(rate(http_server_errors_total[5m])) / sum(rate(http_server_request_total[5m])) * 100
# 메모리 사용률
container_memory_usage_bytes / container_memory_limit_bytes * 100시각화 옵션
차트 유형
| 유형 | 용도 |
|---|---|
| Line Chart | 시계열 데이터 추이 |
| Area Chart | 누적 데이터, 비율 |
| Bar Chart | 비교, 분포 |
| Histogram | 분포, 백분위수 |
| Table | 정확한 값 확인 |
시간 범위
- 빠른 선택: 15분, 1시간, 6시간, 24시간, 7일
- 커스텀: 특정 시작/종료 시간 지정
새로고침 간격
- Off (수동)
- 10초, 30초, 1분, 5분
수집되는 메트릭
시스템 메트릭 (hostmetrics)
| 메트릭 | 설명 |
|---|---|
system_cpu_utilization |
CPU 사용률 |
system_memory_usage |
메모리 사용량 |
system_disk_io |
디스크 I/O |
system_network_io |
네트워크 I/O |
system_filesystem_usage |
파일시스템 사용량 |
Kubernetes 메트릭 (kubeletstats)
| 메트릭 | 설명 |
|---|---|
k8s_node_cpu_utilization |
노드 CPU 사용률 |
k8s_node_memory_usage |
노드 메모리 사용량 |
k8s_pod_cpu_usage |
파드 CPU 사용량 |
k8s_pod_memory_usage |
파드 메모리 사용량 |
container_cpu_usage |
컨테이너 CPU 사용량 |
container_memory_usage |
컨테이너 메모리 사용량 |
애플리케이션 메트릭 (APM Agent)
| 메트릭 | 설명 |
|---|---|
http_server_request_duration_seconds |
HTTP 요청 지연시간 |
http_server_request_total |
HTTP 요청 수 |
rpc_server_duration_seconds |
gRPC 요청 지연시간 |
beyla_network_flow_bytes_total |
네트워크 플로우 |
Kubernetes 상태 메트릭 (kube-state-metrics)
| 메트릭 | 설명 |
|---|---|
kube_deployment_status_replicas |
디플로이먼트 레플리카 수 |
kube_pod_status_phase |
파드 상태 |
kube_node_status_condition |
노드 상태 |
클러스터 필터링
단일 클러스터
system_cpu_utilization{k8s_cluster_name="production-cluster-1"}여러 클러스터
system_cpu_utilization{k8s_cluster_name=~"production-.*"}모든 클러스터 비교
avg by (k8s_cluster_name) (system_cpu_utilization)쿼리 저장
뷰 저장
- 쿼리 작성 후 Save 클릭
- 이름 입력
- 저장
대시보드에 추가
- 쿼리 작성 후 Add to Dashboard 클릭
- 대상 대시보드 선택
- 패널 이름 입력
- 추가
알림 설정
메트릭 기반 알림을 설정합니다.
알림 규칙 생성
- 쿼리 작성
- Create Alert 클릭
- 조건 설정:
- 임계값:
> 80 - 지속 시간: 5분
- 임계값:
- 알림 채널 선택
- 저장
자세한 내용은 알림 문서를 참조하세요.
유용한 쿼리 예시
CPU 사용률 Top 10 파드
topk(10,
sum by (k8s_pod_name, k8s_namespace_name) (
rate(container_cpu_usage_seconds_total[5m])
)
)메모리 사용률 높은 네임스페이스
sum by (k8s_namespace_name) (container_memory_usage_bytes)
/
sum by (k8s_namespace_name) (container_memory_limit_bytes)
* 100에러율
sum(rate(http_server_errors_total[5m]))
/
sum(rate(http_server_request_total[5m]))
* 100P95 응답 시간
histogram_quantile(0.95,
sum by (le, service_name) (
rate(http_server_request_duration_seconds_bucket[5m])
)
)노드별 네트워크 트래픽
sum by (k8s_node_name) (
rate(system_network_io_bytes_total{direction="transmit"}[5m])
)문제 해결
메트릭이 표시되지 않음
- 시간 범위 확인
- 레이블 필터 확인
- 메트릭 존재 여부 확인:
{__name__=~"system.*"}
쿼리 오류
- PromQL 문법 확인
- 메트릭 이름 정확성 확인
- 레이블 이름 확인
데이터 공백
- OTel Collector 상태 확인
- 수집 간격 확인
- Agent 클러스터 연결 상태 확인
다음 단계
- 대시보드 - 메트릭 대시보드 생성
- 알림 - 메트릭 기반 알림 설정
- 인프라스트럭처 - 인프라 모니터링
- 서비스 - APM 서비스 모니터링