노드 정책
경로: 클러스터 > 노드 최적화 > 노드 정책
노드 Autoscaler의 동작 정책을 정의합니다. 노드 스케줄에서 시간대별로 이 정책을 적용하여 노드 수를 자동으로 조정합니다.
화면 구성
ⓘ 노드 정책은 지정된 스케줄에 따라 적용됩니다. 정책을 활성화하려면 스케줄을 설정하세요.
정책 목록 테이블
| 컬럼 | 설명 |
|---|---|
| 정책 이름 | 정책 이름 |
| 정책 설명 | 정책 설명 |
| 인스턴스 타입 | 대상 인스턴스 타입 |
| 노드 범위 | 최소-최대 노드 수 |
| 초과 사용률 | 초과 사용률 (%) |
| 작업 | 수정 / 삭제 |
위 스크린샷의 정책 테이블 참조
정책 생성
"정책 생성" 버튼을 클릭하여 새 정책을 생성합니다.
공통 입력 필드
| 필드 | 타입 | 기본값/예시 | 설명 |
|---|---|---|---|
| 정책 이름 | 텍스트 입력 | - | 정책을 식별하는 고유한 이름입니다. 스케줄에서 정책을 선택할 때 이 이름이 표시되므로, 용도를 파악하기 쉬운 이름을 사용하세요. (예: prod-business-hours, dev-night-scale-down) |
| 설명 | 텍스트 입력 | 선택 | 정책의 목적이나 적용 조건을 자유롭게 기술합니다. 팀원들이 정책의 의도를 파악할 수 있도록 간략한 설명을 입력하는 것을 권장합니다. |
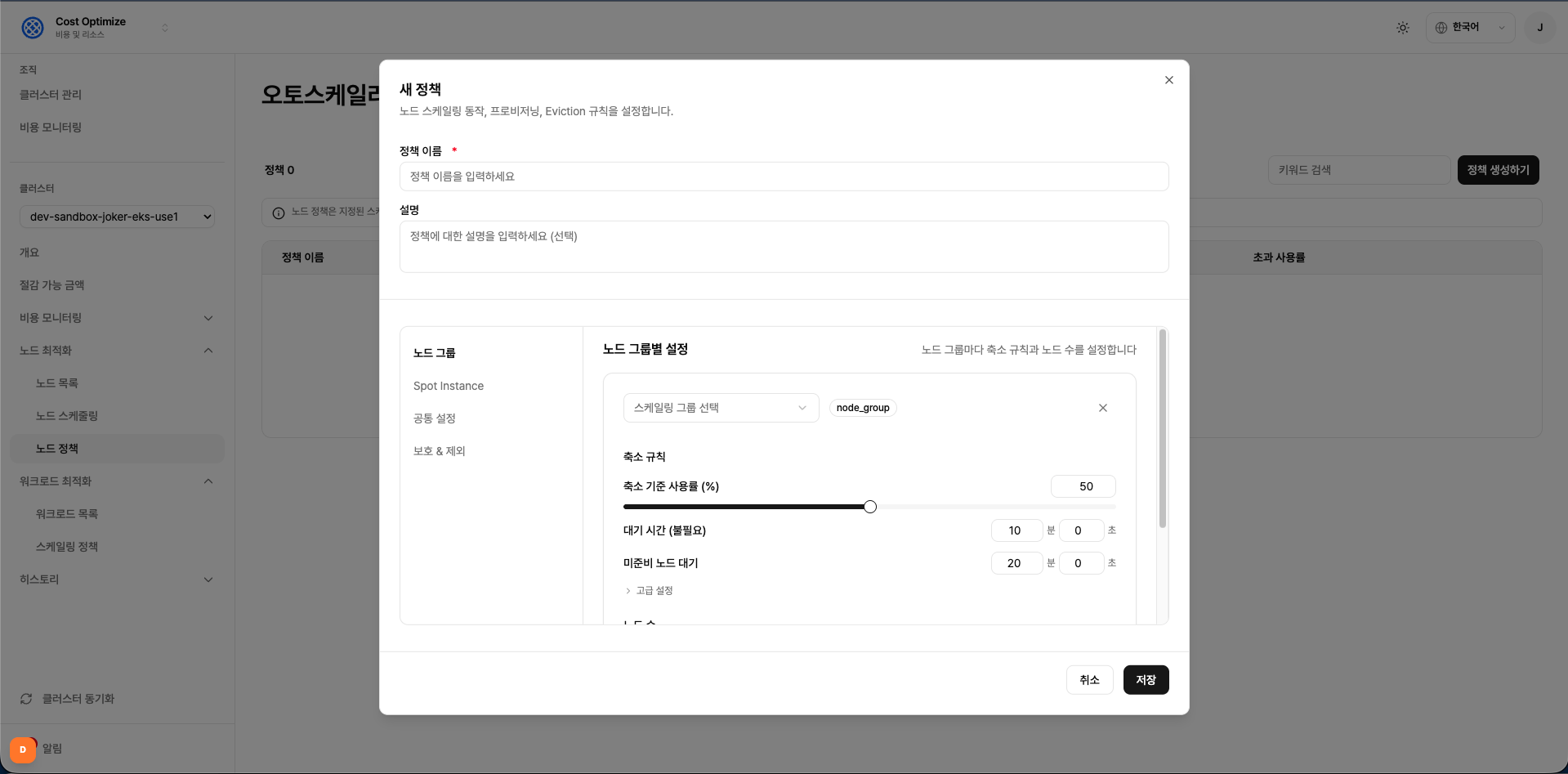
1. 노드 그룹 탭 — 노드 그룹별 설정
노드 그룹마다 축소 규칙과 노드 수를 설정합니다.
클러스터 내 여러 노드 그룹에 서로 다른 축소 규칙을 적용할 수 있습니다. + 노드 그룹 추가 버튼으로 그룹을 추가하세요.
스케일링 그룹
| 필드 | 타입 | 기본값/예시 | 설명 |
|---|---|---|---|
| 스케일링 그룹 선택 | 드롭다운 | skuber-optimized-spot-ng |
이 정책을 적용할 노드 그룹을 선택합니다. 클러스터에 등록된 노드 그룹 목록이 표시됩니다. 노드 그룹마다 독립적인 축소 규칙과 노드 수를 설정할 수 있습니다. |
축소 규칙
Cluster Autoscaler가 노드를 축소(scale-down)할 시점을 결정하는 조건입니다.
노드의 실제 리소스 사용률이 기준값 이하로 떨어지고, 지정한 대기 시간이 지나면 해당 노드를 클러스터에서 제거합니다.
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 축소 기준 사용률 (%) | 슬라이더 | 50 | 노드의 CPU 또는 메모리 요청량(Request)의 합이 이 값 이하일 때 해당 노드를 축소 후보로 판단합니다. 예를 들어 50%로 설정하면, 노드에 할당된 Pod들의 리소스 요청 합계가 노드 전체 용량의 50% 미만일 때 축소 대상이 됩니다. 값이 낮을수록 축소가 보수적으로 이루어지고, 높을수록 공격적으로 노드를 줄입니다. |
| 대기 시간 (불필요) — 분/초 | 숫자 입력 | 10분 0초 | 노드가 축소 기준 사용률 이하로 떨어진 후, 실제로 노드를 제거하기까지 기다리는 시간입니다. 이 시간 동안 사용률이 다시 올라가면 축소가 취소됩니다. 트래픽 변동이 잦은 환경에서는 이 값을 충분히 크게 설정하여 불필요한 스케일 다운을 방지하세요. |
| 미준비 노드 대기 — 분/초 | 숫자 입력 | 20분 0초 | 노드가 NotReady 상태로 전환된 후, 해당 노드를 강제로 제거하기까지 기다리는 시간입니다. 이 시간이 지나도 노드가 정상화되지 않으면 Autoscaler가 노드를 클러스터에서 제거합니다. 네트워크 불안정이나 일시적인 장애로 인한 오탐을 방지하기 위해 적절한 여유 시간을 설정하세요. |
고급 설정
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| GPU 축소 기준 (%) | 슬라이더 | 50 | GPU 노드 그룹에 대해 별도로 적용되는 축소 기준 사용률입니다. GPU 리소스는 CPU/메모리와 달리 부분 할당이 어렵기 때문에 별도 임계값으로 관리합니다. GPU 워크로드가 없는 노드 그룹에서는 이 값이 무시됩니다. |
| DaemonSet 사용률 포함 | 토글 | ON | 노드 사용률을 계산할 때 DaemonSet Pod의 리소스 요청량을 포함할지 여부를 설정합니다. ON: DaemonSet Pod의 리소스도 사용률에 포함하여 계산합니다. 이 경우 DaemonSet 자원 점유로 인해 축소가 보수적으로 동작합니다. OFF: DaemonSet Pod는 사용률 계산에서 제외됩니다. 모든 노드에 기본 배포되는 DaemonSet을 무시하고 사용자 워크로드 중심으로 판단합니다. |
노드 수
Autoscaler가 유지해야 할 노드 그룹의 최소·희망·최대 노드 수를 지정합니다.
스케일 업/다운 시 이 범위를 벗어나지 않도록 제한됩니다.
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 최소 | 숫자 입력 | - | Autoscaler가 노드를 아무리 축소해도 유지해야 하는 최소 노드 수입니다. 0으로 설정하면 트래픽이 없을 때 노드 그룹을 완전히 비울 수 있습니다. 서비스 가용성을 위해 최소 1 이상을 권장합니다. |
| 희망 | 숫자 입력 | - | 초기 또는 스케줄 적용 시 목표로 하는 노드 수입니다. 최소와 최대 사이의 값이어야 하며, Autoscaler가 이 수를 기준으로 스케일을 조정합니다. |
| 최대 | 숫자 입력 | - | 트래픽이 급증해도 이 수를 초과하여 노드를 추가하지 않습니다. 클라우드 비용 상한을 제어하는 역할을 하므로, 예상 최대 부하를 고려하여 설정하세요. |
+ 노드 그룹 추가 버튼으로 그룹 추가 가능
2. Spot Instance 탭 — SPOT INSTANCE 설정
Spot Instance 노드 풀을 설정합니다.
Spot Instance는 온디맨드 인스턴스보다 최대 90% 저렴하지만, 클라우드 공급자에 의해 언제든지 회수될 수 있습니다. 회수 시 다른 인스턴스 타입으로 자동 대체되므로 여러 타입을 지정하는 것을 권장합니다.
| 필드 | 타입 | 기본값/예시 | 설명 |
|---|---|---|---|
| 인스턴스 타입 | 텍스트 입력 (콤마 구분) | m5.xlarge,c5.xlarge,r5.large |
Spot Instance로 사용할 EC2 인스턴스 타입을 콤마(,)로 구분하여 입력합니다. 여러 타입을 지정하면 특정 타입의 Spot 재고가 부족할 때 다른 타입으로 자동 대체됩니다. 비슷한 vCPU와 메모리 사양을 가진 다양한 타입을 나열할수록 가용성이 높아집니다. 유효하지 않은 타입은 자동으로 제외되며, 유효한 값이 하나도 없으면 최소 사양 인스턴스로 대체됩니다. |
3. 공통 설정 탭 — CLUSTER AUTOSCALER
클러스터 전체에 적용되는 Autoscaler의 동작 방식을 설정합니다.
노드 그룹 탭의 설정이 그룹별 규칙이라면, 이 탭의 설정은 Autoscaler 엔진 자체의 동작을 제어합니다.
기본 설정
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 축소(Scale Down) 활성화 | 토글 | ON | Cluster Autoscaler의 노드 축소 기능을 전체적으로 활성화하거나 비활성화합니다. ON: 사용률이 낮은 노드를 자동으로 줄입니다. OFF: 노드 추가(Scale Up)는 동작하지만 축소는 하지 않습니다. 배포나 점검 중에 일시적으로 축소를 막고 싶을 때 OFF로 설정하세요. |
| 동시 처리 노드 수 | 숫자 입력 | 10 | Autoscaler가 한 번의 스캔 사이클에서 동시에 축소 처리할 수 있는 최대 노드 수입니다. 값이 클수록 빠르게 축소되지만, 동시에 많은 노드가 제거되면 실행 중인 Pod가 재스케줄링 부하를 받을 수 있습니다. 클러스터 규모에 맞게 조정하세요. |
고급 Autoscaler 설정
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 노드 그룹 선택 전략 (Expander) | 드롭다운 | Random | 스케일 업 시 여러 노드 그룹 중 어느 그룹에 노드를 추가할지 결정하는 전략입니다. Random: 가능한 노드 그룹 중 무작위로 선택합니다. 특별한 우선순위가 없을 때 적합합니다. 이 외에도 least-waste(리소스 낭비 최소화), most-pods(가장 많은 Pod를 스케줄할 수 있는 그룹), priority(우선순위 기반) 등의 전략이 있습니다. |
| CA 스캔 주기 — 분/초 | 숫자 입력 | 0분 10초 | Autoscaler가 클러스터 상태를 확인하고 스케일 조정 필요 여부를 판단하는 주기입니다. 기본값은 10초이며, 값이 짧을수록 빠르게 반응하지만 API 서버 부하가 증가합니다. |
| Graceful Termination 최대 대기 (초) | 숫자 입력 | 600 | 노드를 축소할 때 해당 노드의 Pod들이 안전하게 종료되기를 기다리는 최대 시간(초)입니다. 이 시간 내에 Pod가 정상 종료되지 않으면 강제로 제거합니다. 장시간 실행되는 배치 작업이 있는 경우 이 값을 충분히 크게 설정하세요. |
| 노드 프로비저닝 최대 대기 — 분/초 | 숫자 입력 | 15분 0초 | 새 노드가 추가된 후 해당 노드가 Ready 상태가 될 때까지 기다리는 최대 시간입니다. 이 시간이 지나도 노드가 준비되지 않으면 Autoscaler는 해당 노드를 실패로 처리합니다. 인스턴스 부팅 및 초기화 시간이 긴 환경에서는 값을 늘리세요. |
| 빈 노드 DaemonSet Eviction | 토글 | OFF | 노드를 축소할 때 DaemonSet Pod만 남은 노드를 빈 노드로 간주하여 제거할지 여부를 설정합니다. ON: DaemonSet Pod만 있는 노드도 사용자 워크로드가 없는 빈 노드로 보고 축소 대상에 포함합니다. OFF: DaemonSet Pod가 있으면 빈 노드로 간주하지 않아 축소하지 않습니다. |
축소/확장 지연
스케일 이벤트 발생 후 즉시 다음 스케일 조정이 일어나지 않도록 쿨다운 시간을 설정합니다.
짧은 시간 내에 반복적인 스케일 조정(flapping)을 방지하는 역할을 합니다.
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 노드 추가 후 대기 — 분/초 | 숫자 입력 | 5분 0초 | 노드가 추가(Scale Up)된 직후, 다음 축소(Scale Down) 평가를 시작하기까지 대기하는 시간입니다. 방금 추가된 노드가 충분히 활용되기 전에 다시 제거되는 것을 방지합니다. |
| 실패 후 대기 — 분/초 | 숫자 입력 | 1분 0초 | 스케일 조정 시도가 실패했을 때, 다음 재시도까지 대기하는 시간입니다. 반복 실패로 인한 불필요한 API 호출을 줄입니다. |
| 새 Pod 대기 — 분/초 | 숫자 입력 | 2분 0초 | 새로운 Pod가 스케줄링된 후, 해당 Pod에 의한 스케일 업 판단을 시작하기까지 대기하는 시간입니다. Pod가 기존 노드에 배치될 수 있는 여유를 주기 위한 설정입니다. |
POD 재배치
노드 간 Pod를 재배치하여 균형을 맞춥니다.
Descheduler가 사용률 불균형을 감지했을 때, 어느 수준부터 재배치를 시작하고 어디를 목표로 할지 정의합니다.
아래 CPU/MEM 슬라이더는 저사용 → 목표 → 과부하 구간을 나타내는 시각적 기준선입니다.
저사용 판단 조건은 CPU 및 MEM 할당률을 AND 조건으로 처리합니다.
과부하 판단 조건은 CPU 및 MEM 할당률을 OR 조건으로 처리합니다.
| 구분 | 항목 | 타입 | 기본값 | 설명 |
|---|---|---|---|---|
| 저사용 기준 | CPU (%) | 슬라이더 | 60 | 노드의 전체 CPU 용량 대비 Pod들의 CPU Request 총합이 이 값(60%) 미만인 노드를 저사용 노드로 간주합니다. 이 노드의 Pod를 다른 노드로 이동시켜 노드 수를 줄이는 방향으로 동작합니다. |
| 저사용 기준 | MEM (%) | 슬라이더 | 60 | Pod들의 메모리 Request 총합이 이 값 미만인 노드를 저사용 노드로 판단합니다. |
| 목표 사용률 | CPU (%) | 슬라이더 | 70 | Pod 재배치 시, 대상 노드의 CPU Request 할당률이 이 값을 초과하지 않도록 밸런스를 맞춥니다. 재배치 후 도달해야 할 균형 상태의 목표 사용률입니다. |
| 목표 사용률 | MEM (%) | 슬라이더 | 70 | Pod 재배치 시, 대상 노드의 메모리 Request 할당률이 이 값을 초과하지 않도록 밸런스를 맞춥니다. |
| 과부하 기준 | CPU (%) | 슬라이더 | 80 | 노드의 전체 CPU 용량 대비 Pod들의 CPU Request 총합이 이 값(80%)을 초과한 노드는 과부하 노드로 간주됩니다. 이 노드의 Pod를 사용률이 낮은 노드로 분산시킵니다. |
| 과부하 기준 | MEM (%) | 슬라이더 | 80 | Pod들의 메모리 Request 총합이 이 값을 초과하면 과부하 노드로 판단합니다. |
4. 보호 & 제외 탭
보호 규칙
이동/제거에서 제외할 대상을 지정합니다.
Descheduler나 Autoscaler가 Pod를 이동하거나 노드를 축소할 때, 아래 조건에 해당하는 Pod는 영향을 받지 않도록 보호합니다.
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 배치 가능 노드만 이동 | 토글 | ON | ON: Pod를 이동하기 전에, 해당 Pod가 다른 노드에 실제로 스케줄될 수 있는지 확인합니다. 대안 노드가 없으면 이동을 시도하지 않아 서비스 중단을 방지합니다. OFF: 가용 노드 확인 없이 이동을 시도합니다. 예외적인 상황에서만 OFF를 사용하세요. |
| 최소 Pod 수명 보장 — 분/초 | 숫자 입력 | 0분 0초 | 생성된 지 이 시간이 지나지 않은 Pod는 이동 대상에서 제외합니다. 예를 들어 5분으로 설정하면, 방금 배포된 Pod가 안정화되기 전에 재배치되는 것을 방지합니다. 0으로 설정하면 수명 제한 없이 모든 Pod가 이동 대상이 됩니다. |
고급 보호 설정
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 로컬 스토리지 Pod 보호 | 토글 | ON | ON: emptyDir, hostPath 등 로컬 스토리지를 마운트하여 사용하는 Pod는 이동 대상에서 제외합니다. 로컬 데이터가 유실될 수 있기 때문입니다. OFF: 로컬 스토리지 사용 여부와 무관하게 이동 대상에 포함될 수 있습니다. |
| DaemonSet Pod 보호 | 토글 | ON | ON: DaemonSet으로 배포된 Pod(예: 로그 수집기, 모니터링 에이전트)는 이동 대상에서 제외합니다. DaemonSet Pod는 각 노드에 하나씩 고정 배포되는 특성상 재배치가 의미 없습니다. OFF: DaemonSet Pod도 이동 대상에 포함합니다. |
| PVC Pod 보호 | 토글 | OFF | ON: PersistentVolumeClaim(PVC)을 사용하는 Pod는 이동 대상에서 제외합니다. PVC가 특정 가용 영역(AZ)에 종속된 경우, 다른 노드로 이동하면 볼륨을 마운트하지 못할 수 있습니다. OFF: PVC를 사용하더라도 이동 대상에 포함할 수 있습니다. 멀티 AZ를 지원하는 스토리지 클래스 환경에서는 OFF로 설정해도 안전합니다. |
| 실패한 Bare Pod 보호 | 토글 | ON | ON: ReplicaSet이나 Deployment 없이 직접 생성된(kubectl run 등) 실패 Pod는 이동 대상에서 제외합니다. 이 Pod들은 이동해도 자동으로 재생성되지 않기 때문에 데이터 손실이나 작업 중단이 발생할 수 있습니다. OFF: 실패한 Bare Pod도 이동 대상에 포함합니다. |
이상 POD 정리
재시작이 반복되는 비정상 Pod를 자동으로 제거합니다.
| 필드 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| 자동 정리 | 토글 | OFF | ON: CrashLoopBackOff 등 비정상 상태로 반복 재시작되는 Pod를 자동으로 감지하여 제거합니다. Pod를 제거하면 상위 컨트롤러(Deployment 등)가 새 Pod를 재생성합니다. OFF: 비정상 Pod가 있어도 자동으로 제거하지 않습니다. 장애 원인 분석이 필요한 경우 OFF를 유지하세요. |
제외 설정
| 필드 | 타입 | 기본값/예시 | 설명 |
|---|---|---|---|
| 제외 네임스페이스 | 태그 입력 | kube-system |
이 네임스페이스에 속한 Pod는 Eviction(퇴거) 대상에서 완전히 제외됩니다. 네임스페이스 이름을 입력하고 Enter를 눌러 추가합니다. 여러 네임스페이스를 등록할 수 있으며, 시스템 컴포넌트가 실행되는 네임스페이스(예: kube-system, monitoring)는 제외하는 것을 권장합니다. |
| 시스템 네임스페이스 포함 | 토글 | OFF | ON: kube-system 등 시스템 NS에 있는 Pod도 Eviction 대상에 포함합니다. OFF: 시스템 네임스페이스의 Pod는 Eviction에서 보호됩니다. 클러스터 안정성을 위해 OFF를 유지하는 것을 강력히 권장합니다. |
5. Pod 보호 설정 (스케일 다운 / 퇴거 제외)
특정 Pod를 Cluster Autoscaler(CA) scale-down 및 Descheduler eviction 대상에서 제외하기 위한 설정입니다.
Cluster Autoscaler — Node Scale-down 보호
Pod에 아래 annotation을 추가하면 해당 Pod가 존재하는 Node는 CA scale-down 대상에서 제외됩니다.
metadata:
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"- 타입: Annotation (Kubernetes CA 네이티브 지원)
- 동작: 해당 annotation이 있는 Pod가 실행 중인 Node는 drain하지 않음
Descheduler — Pod Eviction 보호
Pod에 아래 label을 추가하면 Descheduler eviction 대상에서 제외됩니다.
metadata:
labels:
skuberplus.com/safe-to-evict: "false"- 타입: Label (Descheduler base policy의 labelSelector
NotIn ["false"]로 필터링) - 동작: 해당 label이 있는 Pod는 Descheduler가 재배치하지 않음
적용 예시
# CA 보호: annotation 추가
kubectl annotate pods <pod-name> cluster-autoscaler.kubernetes.io/safe-to-evict=false
# Descheduler 보호: label 추가
kubectl label pods <pod-name> skuberplus.com/safe-to-evict=false요약
| 보호 대상 | 키 | 타입 | 값 |
|---|---|---|---|
| CA scale-down | cluster-autoscaler.kubernetes.io/safe-to-evict |
Annotation | "false" |
| Descheduler eviction | skuberplus.com/safe-to-evict |
Label | "false" |
정책 관리
수정
정책 목록에서 수정 버튼을 클릭합니다.
⚠️ 주의: 현재 스케줄에 의해 적용 중인 정책을 수정하면 즉시 반영됩니다.
삭제
정책 목록에서 삭제 버튼을 클릭합니다.
⚠️ 주의: 스케줄에 연결된 정책은 삭제할 수 없습니다. 먼저 스케줄에서 정책 연결을 해제하세요.