인프라스트럭처
최종 수정: 2026. 1. 16.
인프라스트럭처
Kubernetes 클러스터 인프라를 모니터링하는 방법을 안내합니다.
개요
인프라스트럭처 모니터링은 모든 Agent Cluster의 Kubernetes 리소스 상태를 실시간으로 확인할 수 있습니다.
모니터링 대상
| 리소스 | 수집 메트릭 |
|---|---|
| Nodes | CPU, 메모리, 디스크, 네트워크 |
| Pods | CPU, 메모리, 재시작 횟수, 상태 |
| Containers | CPU, 메모리, 리소스 제한 |
| Deployments | 레플리카 상태, 업데이트 상태 |
| StatefulSets | 레플리카 상태 |
| DaemonSets | 노드별 상태 |
| Jobs | 실행 상태, 완료 상태 |
| Volumes | 용량, 사용량 |
인프라 대시보드 접근
- 좌측 메뉴에서 Infrastructure 클릭
- 하위 메뉴에서 원하는 카테고리 선택:
- Kubernetes
- Hosts
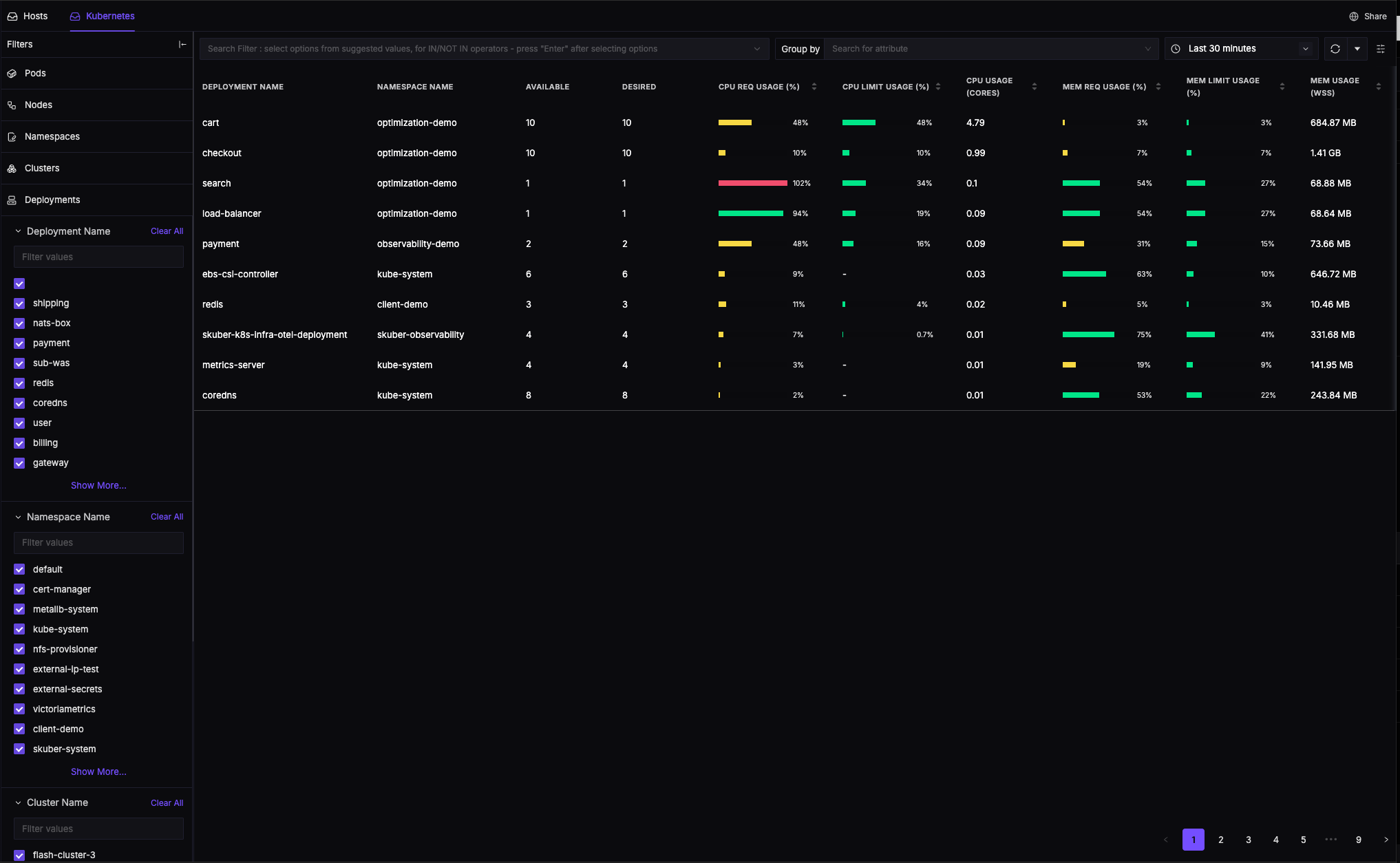
Kubernetes 모니터링
클러스터 개요
Infrastructure > Kubernetes > Clusters
모든 Agent Cluster의 상태를 한눈에 확인:
| 정보 | 설명 |
|---|---|
| Cluster Name | 클러스터 이름 |
| Nodes | 총 노드 수 / Ready 노드 수 |
| Pods | 총 파드 수 / Running 파드 수 |
| CPU Usage | 클러스터 전체 CPU 사용률 |
| Memory Usage | 클러스터 전체 메모리 사용률 |
노드 모니터링
Infrastructure > Kubernetes > Nodes
각 노드의 상세 상태:
| 메트릭 | 설명 |
|---|---|
| CPU Utilization | CPU 사용률 (%) |
| Memory Usage | 메모리 사용량 / 총 용량 |
| Disk I/O | 디스크 읽기/쓰기 속도 |
| Network I/O | 네트워크 송수신 속도 |
| Pod Count | 실행 중인 파드 수 |
| Conditions | Ready, MemoryPressure, DiskPressure |
노드 상세 보기
노드를 클릭하면:
- 시계열 리소스 그래프
- 해당 노드의 파드 목록
- 노드 이벤트
파드 모니터링
Infrastructure > Kubernetes > Pods
| 메트릭 | 설명 |
|---|---|
| Status | Running, Pending, Failed 등 |
| CPU Usage | CPU 사용량 |
| Memory Usage | 메모리 사용량 |
| Restarts | 재시작 횟수 |
| Age | 생성 후 경과 시간 |
파드 필터링
- Cluster: 특정 클러스터만 표시
- Namespace: 특정 네임스페이스만 표시
- Status: 특정 상태만 표시
파드 상세 보기
파드를 클릭하면:
- 컨테이너별 리소스 사용량
- 파드 이벤트
- 관련 로그 링크
- 관련 트레이스 링크
Deployments 모니터링
Infrastructure > Kubernetes > Deployments
| 정보 | 설명 |
|---|---|
| Name | 디플로이먼트 이름 |
| Namespace | 네임스페이스 |
| Replicas | 원하는 / 준비된 / 사용 가능 |
| CPU Usage | 전체 레플리카 CPU 합계 |
| Memory Usage | 전체 레플리카 메모리 합계 |
StatefulSets / DaemonSets
동일한 형식으로 StatefulSet과 DaemonSet 상태를 확인할 수 있습니다.
Jobs
Infrastructure > Kubernetes > Jobs
| 정보 | 설명 |
|---|---|
| Name | Job 이름 |
| Status | Running, Succeeded, Failed |
| Duration | 실행 시간 |
| Completions | 완료된 / 전체 |
Volumes
Infrastructure > Kubernetes > Volumes
| 정보 | 설명 |
|---|---|
| PVC Name | PersistentVolumeClaim 이름 |
| Capacity | 총 용량 |
| Used | 사용 중인 용량 |
| Usage % | 사용률 |
| Pod | 마운트된 파드 |
Hosts 모니터링
Infrastructure > Hosts
각 노드의 호스트 시스템 메트릭:
CPU 메트릭
| 메트릭 | 설명 |
|---|---|
| CPU Utilization | 전체 CPU 사용률 |
| User | 사용자 프로세스 CPU |
| System | 시스템 프로세스 CPU |
| I/O Wait | I/O 대기 시간 |
메모리 메트릭
| 메트릭 | 설명 |
|---|---|
| Used | 사용 중인 메모리 |
| Free | 여유 메모리 |
| Cached | 캐시된 메모리 |
| Buffers | 버퍼 메모리 |
디스크 메트릭
| 메트릭 | 설명 |
|---|---|
| Read Bytes/s | 초당 읽기 바이트 |
| Write Bytes/s | 초당 쓰기 바이트 |
| Read IOPS | 초당 읽기 작업 수 |
| Write IOPS | 초당 쓰기 작업 수 |
네트워크 메트릭
| 메트릭 | 설명 |
|---|---|
| Received Bytes/s | 초당 수신 바이트 |
| Transmitted Bytes/s | 초당 송신 바이트 |
| Errors | 네트워크 에러 수 |
| Dropped | 드롭된 패킷 수 |
클러스터 비교
멀티클러스터 뷰
여러 클러스터를 동시에 선택하여 비교:
- 클러스터 필터에서 여러 클러스터 선택
- 동일한 메트릭을 클러스터별로 비교
리소스 사용량 비교
Cluster A: CPU 45%, Memory 60%
Cluster B: CPU 78%, Memory 82% ← 주의 필요
Cluster C: CPU 32%, Memory 45%알림 설정
인프라 메트릭 기반 알림:
노드 알림
- CPU 사용률 > 80% (5분 이상)
- 메모리 사용률 > 85%
- 디스크 사용률 > 90%
- 노드 NotReady 상태
파드 알림
- 파드 재시작 > 3회 (1시간 내)
- 파드 Pending > 5분
- 파드 Failed 상태
디플로이먼트 알림
- 레플리카 부족
- 업데이트 실패
자세한 내용은 알림 문서를 참조하세요.
문제 해결
노드가 표시되지 않음
- Agent Cluster 연결 상태 확인
- kube-state-metrics 상태 확인:
kubectl get pods -n skuber-observability -l app.kubernetes.io/name=kube-state-metrics
메트릭 지연
- OTel Collector 상태 확인
- 수집 간격 확인 (기본 20-30초)
일부 리소스 누락
- RBAC 권한 확인
- 네임스페이스 필터 확인
다음 단계
- 서비스 - APM 서비스 모니터링
- 대시보드 - 커스텀 대시보드 생성
- 알림 - 인프라 알림 설정
- 메트릭 - 메트릭 탐색기